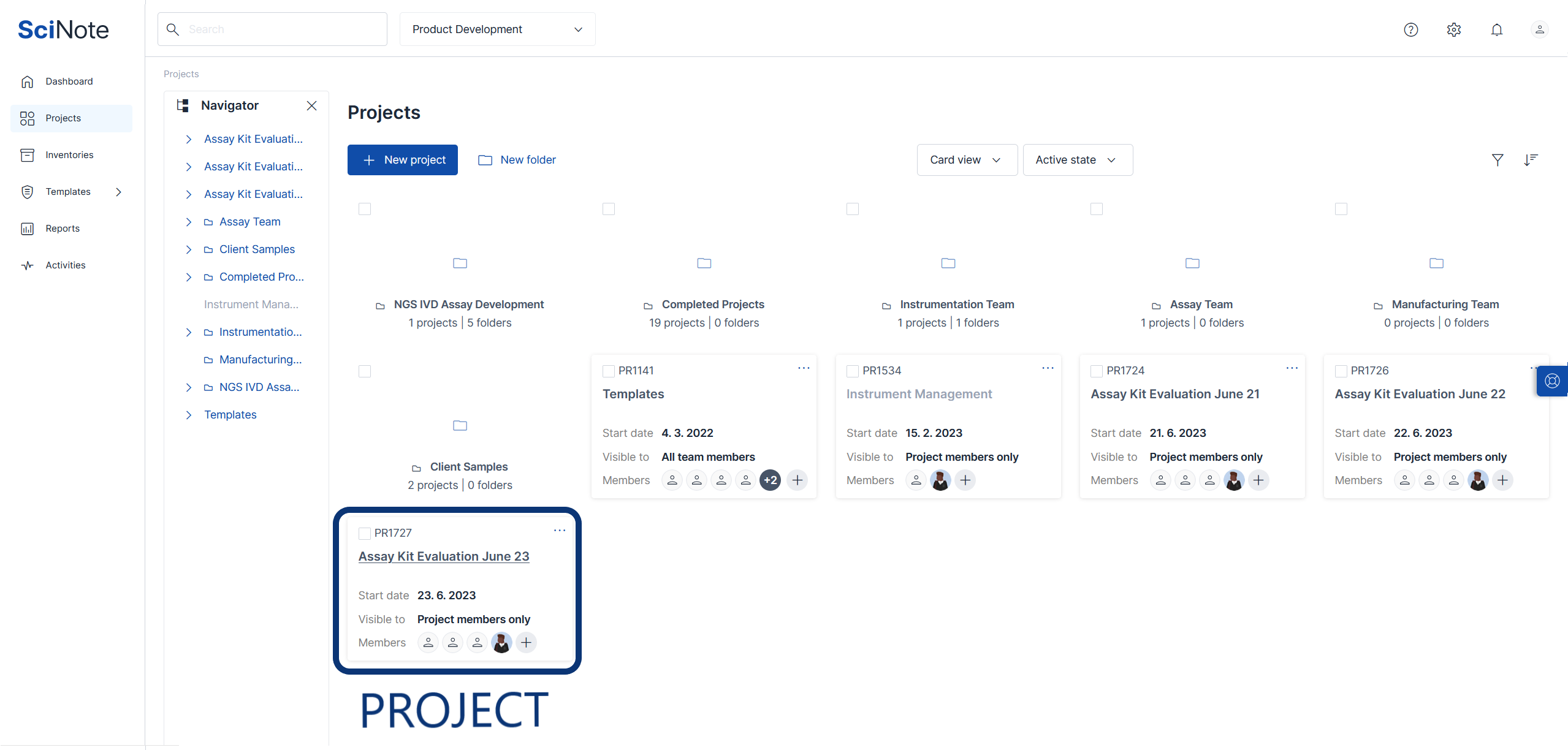
The basic SciNote components are organized into a hierarchical structure:

- Projects - the first structural level of data organization (each table row represents a project).
- Each Project has a unique identifier (Project ID) that is auto-numbered by SciNote and will never change over time. E.g., PR1608
- Team Owners can also create Project Folders and subfolders to further group and organize Projects within the same SciNote Team.
- Each Project has a unique identifier (Project ID) that is auto-numbered by SciNote and will never change over time. E.g., PR1608
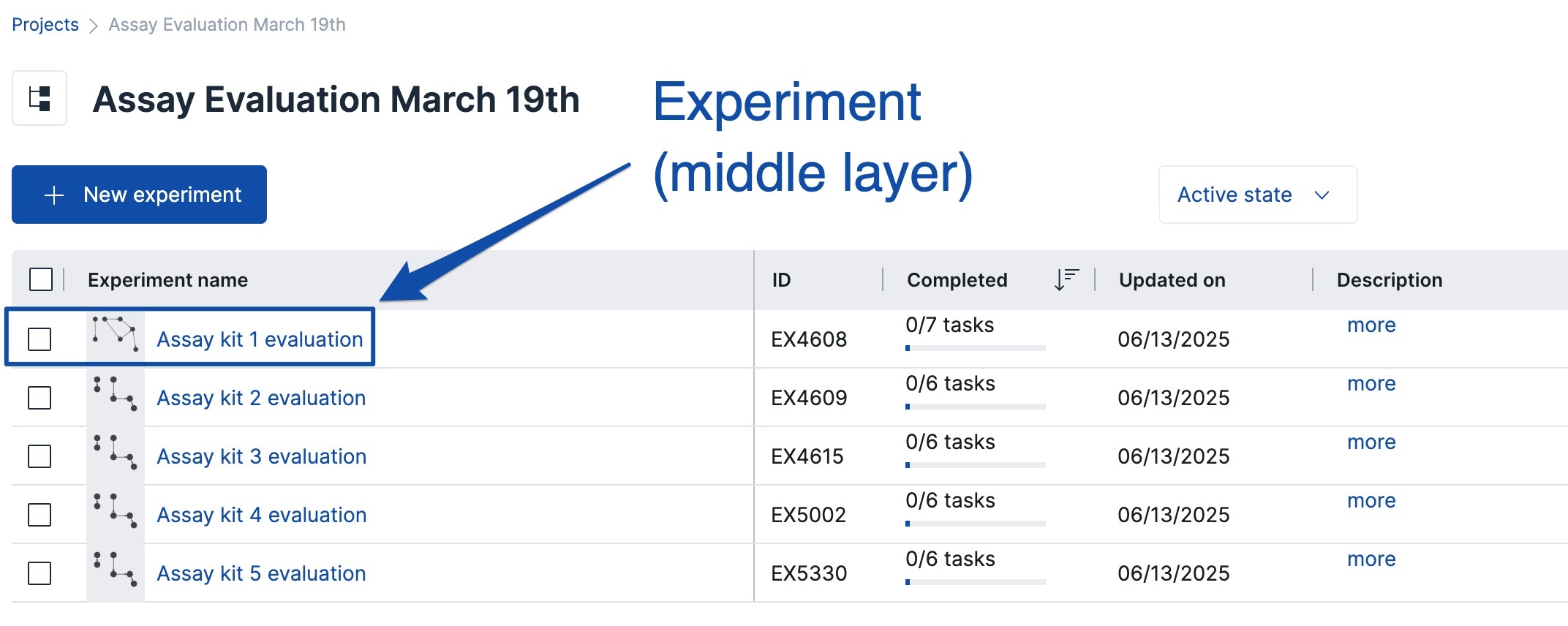
- Experiments - can be thought of as project subfolders. These represent different workflows within the larger project.
- Individual SciNote Experiments can be things like: batches, process development "versions", set time periods, a unique lab process, etc.
- Each Experiment has a unique identifier (Experiment ID) that is auto-numbered by SciNote and will never change over time. E.g., EX4608
-
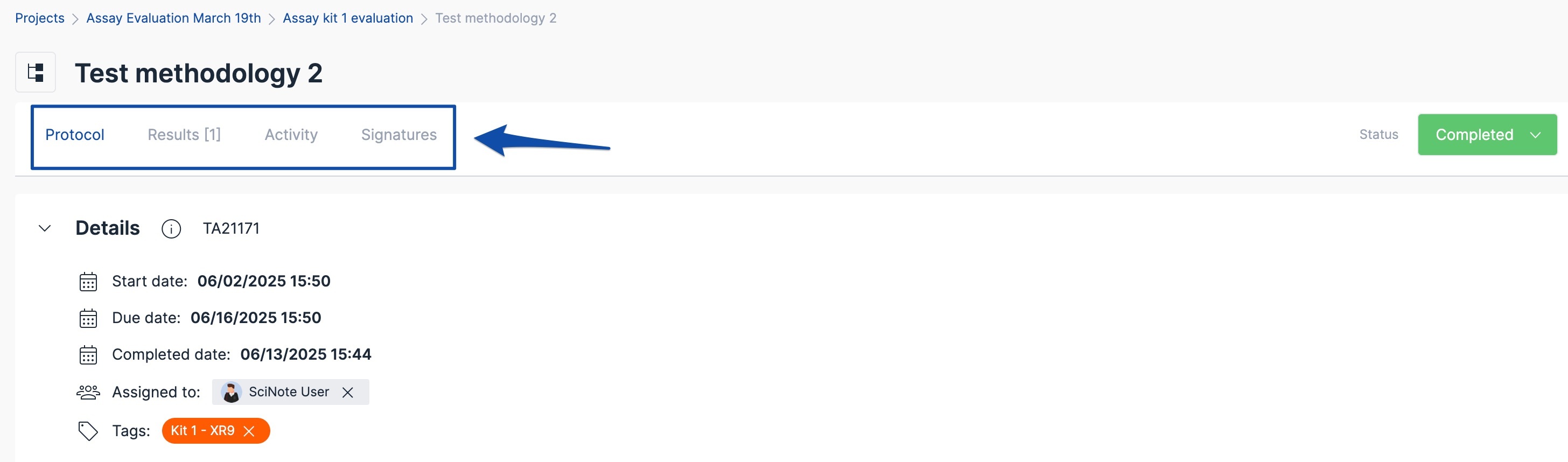
Tasks – can form experimental workflow when connected to each other, or they can be stand-alone units. All of your data will be entered into the tasks.
-
Tasks have due dates, protocol steps and results attached, assigned users (task assigned to), and linked inventory items. The point of data entry in SciNote is the Task!
- Every Task has a unique identifier (Task ID) that is auto-numbered by SciNote and will never change over time. E.g., TA21171
-
Every task also includes an overview of the protocol, results, task activity, signatures history, assigned inventory items, and archived results.
-
For a more detailed explanation of SciNote's structure, read this document.
To learn more about SciNote's structure watch our video.
If you have any additional questions, please contact us at support@scinote.net. For more info about the Premium plans, please request a quote.